
Trunk-Based Development (TBD) es una estrategia de control de versiones que promueve la colaboración continua y la integración frecuente de cambios en una única rama principal del código, conocida como "trunk" o "main". Este enfoque busca minimizar los conflictos de integración y acelerar el ciclo de entrega de software. A continuación, se presenta un resumen detallado de los principios, beneficios y consideraciones clave de TBD.([Atlassian]1, [Harness.io]2)
¿Qué es Trunk-Based Development?
Trunk-Based Development es una práctica de gestión de control de versiones en la que los desarrolladores integran pequeños y frecuentes cambios en una rama principal compartida, denominada "trunk" o "main". Este modelo evita la creación de ramas de desarrollo de larga duración, promoviendo en su lugar la integración continua y la entrega rápida de software.
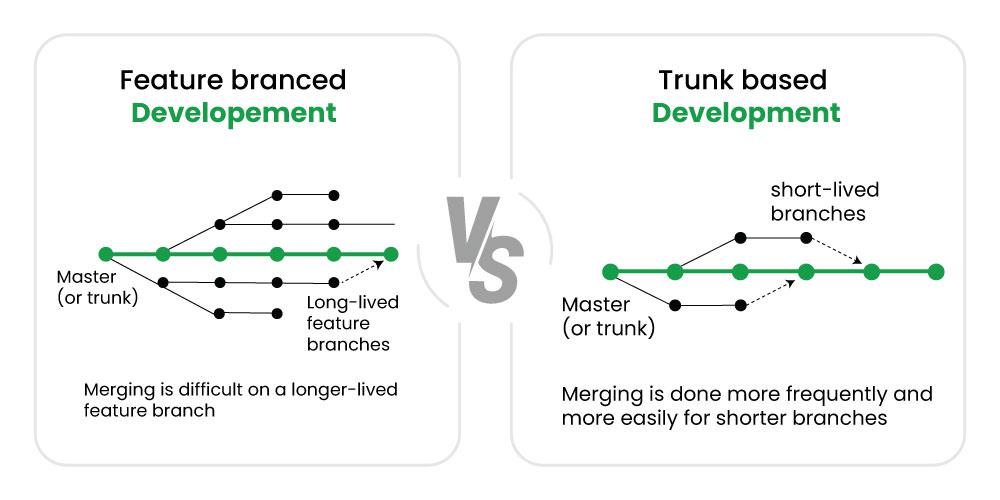
A diferencia de otros enfoques como Git Flow o Feature Branching (en la imagen), que fomentan el uso de múltiples ramas (por ejemplo, develop, release, hotfix, feature/*), Trunk-Based Development busca simplificar el flujo de trabajo y reducir los riesgos de integración tardía.
Mientras Git Flow es útil en entornos con ciclos de lanzamiento largos y estructuras más formales, Trunk-Based Development está más alineado con metodologías ágiles y DevOps, donde la prioridad es la automatización, la productividad y la colaboración constante entre equipos.
Al eliminar la complejidad innecesaria del manejo de ramas prolongadas, esta estrategia facilita el testing automatizado, el deployment continuo y una mayor calidad en el software entregado.
Principios fundamentales de TBD
Los iremos desarrollando a lo largo de este artículo. De momento te los enumero:
- Integración continua: Los desarrolladores integran sus cambios en la rama principal varias veces al día, lo que facilita la detección temprana de errores y reduce los conflictos de integración.
- Ramas de corta duración: Si se utilizan ramas, estas son de vida corta, generalmente de horas o pocos días, y se integran rápidamente al trunk.
- Revisión de código continua: Las revisiones de código se realizan de manera continua y rápida, lo que mejora la calidad del código y facilita la colaboración entre desarrolladores.
- Automatización de pruebas: Se implementan pruebas automatizadas que se ejecutan con cada integración para garantizar la estabilidad y calidad del código.
- Uso de feature flags: Se emplean banderas de características para activar o desactivar funcionalidades en producción sin necesidad de desplegar nuevo código, permitiendo una mayor flexibilidad y control.
Beneficios de Trunk-Based Development
- Reducción de conflictos de integración: Al integrar cambios frecuentemente, se minimizan los conflictos que suelen surgir al fusionar ramas de larga duración.
- Entrega continua: El código en la rama principal está siempre en un estado desplegable, lo que permite realizar entregas frecuentes y rápidas.
- Mejora en la calidad del código: Las revisiones continuas y las pruebas automatizadas contribuyen a mantener un código de alta calidad.
- Mayor colaboración: Al trabajar en una única rama compartida, se fomenta la colaboración y comunicación constante entre los miembros del equipo.
Comparación con GitFlow
Mientras que GitFlow utiliza múltiples ramas de larga duración para gestionar el desarrollo, las correcciones y las versiones, TBD se centra en una única rama principal con integraciones frecuentes. GitFlow puede ser más adecuado para proyectos con ciclos de lanzamiento definidos y necesidades de mantenimiento específicas, mientras que TBD es ideal para equipos que buscan una entrega continua y rápida. ([Harness.io]2)
Paso 1: Establecer una Rama Principal Compartida
Introducción
El primer paso fundamental para adoptar Trunk-Based Development (TBD) es establecer una rama principal compartida como centro neurálgico del desarrollo. Esta rama es comúnmente denominada main o trunk, y todos los desarrolladores integran directamente (o a través de ramas muy breves) su trabajo en ella.
Esta práctica representa un cambio de paradigma frente a otros flujos de trabajo más tradicionales como Git Flow, donde las ramas de desarrollo (develop, feature/*, release/*, hotfix/*) son fundamentales. En TBD, simplificamos la topología del repositorio para maximizar la velocidad de integración y minimizar la divergencia.
¿Por qué una sola rama?
Mantener una única rama principal compartida tiene los siguientes beneficios:
- Evita la deriva de código entre ramas largas.
- Promueve la integración continua, ya que todos los cambios convergen rápidamente.
- Minimiza el coste de la fusión, al hacer merges pequeños y frecuentes.
- Aumenta la visibilidad del estado actual del producto, porque lo que hay en
maines lo que hay.
Pasos para establecerla correctamente
1. Nombrar la rama principal
La convención moderna recomienda usar main como nombre de la rama principal en lugar de master, por razones de claridad y neutralidad. En proyectos más antiguos, puedes renombrar así:
git branch -m master main
git push -u origin main
git symbolic-ref refs/remotes/origin/HEAD refs/remotes/origin/main
2. Bloquear el uso de ramas largas
Configura el entorno de desarrollo y los repositorios (por ejemplo, en GitHub, GitLab o Bitbucket) para:
- Restringir la creación de ramas de larga duración.
- Desalentar el uso de ramas
develop,release, etc. - Establecer reglas claras para pequeñas ramas temporales (máx. 1–2 días).
3. Activar protección y revisión en main
Aunque TBD impulsa la integración frecuente, eso no significa que se omita la calidad. Puedes:
- Activar branch protection rules que exijan que los commits a
mainpasen por PR (pull request). - Requerir revisiones ligeras o rotativas.
- Automatizar pruebas para impedir integraciones defectuosas.
En GitHub, por ejemplo:
Settings > Branches > Branch Protection Rules > Require status checks to pass before merging
4. Automatizar la integración y las pruebas
Cada cambio en main debe:
- Ser testeado automáticamente mediante CI (por ejemplo, GitHub Actions, GitLab CI/CD, CircleCI).
- Lanzar procesos de despliegue automáticos si corresponde (CD).
Este pipeline debe ser rápido (<10 minutos idealmente), confiable y visible para todos.
5. Educar al equipo
Cambiar a TBD requiere compromiso del equipo. Algunas acciones útiles:
- Realizar formaciones o talleres sobre flujo de trabajo con una rama compartida.
- Establecer normas: “nunca rompas
main”, “integra al menos una vez al día”, “usa feature toggles”, etc. - Incentivar la colaboración en cambios grandes para evitar bloqueos.
Buenas prácticas adicionales
- Commits pequeños y atómicos: Evita grandes commits que dificulten las revisiones y el troubleshooting.
- Mensajes de commit claros: Usa convenciones como Conventional Commits (
feat:,fix:,refactor:…). - Feature toggles: Activa/desactiva funcionalidades en producción sin necesidad de ramas largas.
Veamos un ejemplo de como activar una nueva funcionalidad con feature toggle en Python
Supongamos que estás desarrollando una API y quieres introducir una nueva funcionalidad de búsqueda avanzada, pero sin romper la versión actual en producción. En lugar de crear una rama larga, usas un toggle para activarla o no:
# config.py
FEATURE_FLAGS = {
"advanced_search": False # Cambia a True para activarla
}
# main.py
from config import FEATURE_FLAGS
def basic_search():
return "Ejecutando búsqueda básica..."
def advanced_search():
return "Ejecutando búsqueda avanzada con filtros..."
def search():
if FEATURE_FLAGS["advanced_search"]:
return advanced_search()
return basic_search()
if __name__ == "__main__":
print(search())
Ahora hacemos commit, dejando un mensaje claro:
git add main.py config.py
git commit -m "feat: añade feature toggle para búsqueda avanzada"
feat:indica que estás añadiendo una nueva funcionalidad al código (útil para changelogs automatizados).- El resto del mensaje describe claramente qué se está incorporando: el feature toggle para activar o desactivar la búsqueda avanzada.
Otros ejemplos comunes de mensaje en el commit incluirían:
fix: corrige error al desactivar la búsqueda avanzadarefactor: reorganiza lógica de búsqueda sin cambiar funcionalidadtest: añade pruebas unitarias para toggle de búsqueda avanzada
Posibles dificultades
- Rupturas accidentales: Si alguien introduce código defectuoso en
main, todos se ven afectados. Por eso CI y revisión son imprescindibles. - Resistencia al cambio: Equipos acostumbrados a Git Flow pueden tener miedo de "romper cosas". Aquí es clave la formación.
- Cambios grandes: Para grandes refactors o features complejas, usar feature branches de muy corta duración o técnicas como branch by abstraction.
Ejemplo realista
Supón que trabajas con un equipo de 4 desarrolladores. Todos comparten la rama main y se organizan así:
- Cada uno crea una rama
feat/nueva-funcionalidady hace push el mismo día. - Cada PR se revisa rápidamente (máximo 30 minutos desde que se abre).
- Al hacer merge, los tests corren automáticamente.
- Si todo va bien, se despliega en staging automáticamente.
En este contexto, no hay ramas develop, ni release, ni semanas de trabajo sin integración.
Paso 2: Fomentar Integraciones Frecuentes
Uno de los principios esenciales del Trunk-Based Development (TBD) es que los desarrolladores deben integrar sus cambios en la rama principal varias veces al día. Esta práctica, conocida como frequent commits o continuous integration, es vital para mantener un código limpio, coherente y en constante evolución.
Integrar con frecuencia no es solo un hábito técnico, sino una filosofía que prioriza la comunicación continua entre personas, la visibilidad colectiva del código y la responsabilidad compartida del producto.
¿Qué significa integrar con frecuencia?
En el contexto de TBD, "integrar frecuentemente" implica:
- Que cada desarrollador sincroniza su trabajo con el trunk al menos una o dos veces por jornada de trabajo.
- Que las integraciones son pequeñas y manejables, no grandes paquetes de cambios acumulados.
- Que el trunk se mantiene siempre en un estado estable, desplegable y verificable mediante pruebas automáticas.
Beneficios de integrar frecuentemente
1. Reducción de conflictos
Integrar frecuentemente reduce drásticamente los conflictos de fusión (merge conflicts), ya que:
- El código divergente se detecta rápidamente.
- Las diferencias entre desarrolladores se resuelven en horas, no en semanas.
- Se evita la “sorpresa” de cambios incompatibles acumulados.
2. Visibilidad y colaboración
Cuando todos integran con regularidad:
- Todo el equipo ve lo que los demás están haciendo en tiempo real.
- Se fomentan conversaciones técnicas tempranas y constructivas.
- El conocimiento del sistema se distribuye de forma natural.
3. Mejora continua
Las integraciones frecuentes habilitan:
- La mejora constante del producto.
- El feedback inmediato tras cada cambio (gracias a CI/CD).
- La corrección rápida de errores y la iteración ágil.
Requisitos para que funcione
Para que la integración frecuente sea efectiva, deben darse ciertas condiciones técnicas y culturales.
1. Tests automáticos rápidos y fiables
Cada push al trunk debe ejecutar una batería de pruebas. Cuanto más rápido y fiable sea este feedback, más seguro será integrar a menudo.
- Unit tests en segundos.
- Integration tests en minutos.
- Fail fast: que fallen rápido y con mensajes útiles.
2. Integración continua (CI) bien configurada
Herramientas como GitHub Actions, GitLab CI, Jenkins o CircleCI deben estar integradas al repositorio para:
- Ejecutar automáticamente los tests tras cada push o PR.
- Notificar a los desarrolladores del resultado.
- Bloquear merges si los tests fallan.
3. Desacoplamiento y modularidad
Es difícil integrar cambios frecuentemente si el código está muy acoplado. Algunos principios útiles:
- Single Responsibility Principle.
- Micro-commits: cada cambio realiza una tarea clara.
- Uso de interfaces o abstracciones para facilitar refactors incrementales.
4. Pequeños pasos (baby steps)
Romper funcionalidades grandes en pequeños pasos ayuda a:
- Integrar más rápido.
- Probar partes aisladas.
- Usar feature toggles para funcionalidades incompletas.
5. Uso de Feature Flags
Las banderas de características permiten integrar código en producción sin activarlo. Esto:
- Elimina la necesidad de mantener ramas largas.
- Permite pruebas A/B y despliegues progresivos.
- Facilita revertir sin hacer rollback de código.
Técnicas para lograrlo
✅ Commit temprano, commit a menudo
Realiza pequeños commits funcionales y súbelos tan pronto como sea posible.
✅ Push en medio del trabajo
No esperes a terminar todo para hacer push. Es preferible subir parte del trabajo, protegido por un feature flag, a quedarte con días de trabajo fuera del trunk.
✅ Pull frecuente del trunk
Antes de comenzar el día o cada pocas horas:
git pull origin main
Mantener tu entorno sincronizado evita sorpresas desagradables al hacer merge.
✅ Short-lived branches
Si usas ramas de funcionalidad, que duren solo unas horas o un día. Ejemplo:
git checkout -b feat/nueva-validacion
# Haces el cambio
git push origin feat/nueva-validacion
# Abres PR -> CI -> revisión rápida -> merge
Qué evitar
- ❌ Ramas que duran varios días.
- ❌ Esperar a “tenerlo todo listo” para integrar.
- ❌ Introducir cambios grandes sin tests.
- ❌ Integrar sin revisar el estado del trunk (pull).
- ❌ Depender solo de integración manual (sin CI/CD).
Cultura de equipo: un factor clave
Integrar frecuentemente es una práctica que debe estar respaldada por la cultura del equipo. Esto incluye:
- Confianza entre desarrolladores.
- Valentía para subir código incompleto (pero protegido).
- Disciplina para escribir tests desde el principio.
- Revisión rápida y constante de PRs.
- Tolerancia al cambio constante, entendiendo que el código está vivo.
Ejemplo práctico
En un equipo que sigue TBD correctamente:
- Pedro comienza su día, hace
git pull origin main. - Crea una rama
feat/nueva-alerta, y en 2 horas termina la primera parte. - Abre una PR con tests y la etiqueta
#WIP(Work In Progress). - Su compañero Jaime la revisa al momento y sugiere un cambio.
- Pedro lo aplica, se pasa CI, y Jaime mergea a
main. - Al final del día, Pedro ha integrado 3 veces a
main.
Paso 3: Automatizar Pruebas y Despliegues
Introducción
Una de las piedras angulares del Trunk-Based Development es garantizar que cada integración en el trunk sea segura, verificada y potencialmente desplegable. Para lograrlo, la automatización de pruebas y despliegues se vuelve indispensable.
En TBD, los equipos integran cambios varias veces al día. Hacer esto manualmente es insostenible y arriesgado. La única forma de mantener la calidad, velocidad y estabilidad es delegar en un sistema automatizado y confiable que pruebe y despliegue el código de forma continua.
¿Qué significa automatizar pruebas y despliegues?
Automatizar en este contexto implica:
- Ejecutar pruebas automáticas (unitarias, de integración, de extremo a extremo) después de cada cambio en el código.
- Desplegar automáticamente a entornos como staging o incluso producción, si el código pasa todos los controles.
- Eliminar tareas repetitivas y propensas a error, como validaciones manuales, ejecución de scripts o pasos de configuración.
Objetivos de la automatización
- Detectar errores rápidamente Cuanto antes se detecta un bug, más fácil y barato es corregirlo.
- Evitar regressiones Una buena suite de pruebas asegura que los cambios no rompan lo existente.
- Reducir el tiempo entre escribir código y verlo funcionando El feedback inmediato impulsa una mayor productividad y aprendizaje.
- Permitir despliegues frecuentes y seguros La entrega continua es solo posible si hay confianza total en el pipeline automatizado.
Automatización de pruebas
Tipos de pruebas automatizadas
- Unitarias
Prueban funciones o métodos individuales en aislamiento. Son rápidas y fáciles de mantener.
Ejemplo:
pytest,Jest,xUnit. - De integración Verifican que varios módulos colaboren correctamente. Ejemplo: interacción entre API y base de datos.
- End-to-end (E2E)
Simulan el comportamiento del usuario final en todo el sistema.
Ejemplo:
Cypress,Playwright,Selenium. - Contract Testing / API
Garantizan que una API cumpla con el contrato definido, muy útil en microservicios.
Ejemplo:
Pact.
Cuándo y cómo ejecutarlas
- En cada pull request.
- Con cada push a
main. - De forma paralela para reducir tiempos.
- Usando un orquestador CI como:
- GitHub Actions
- GitLab CI/CD
- CircleCI
- Jenkins
- Drone CI
Ejemplo con GitHub Actions:
name: Run Tests
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install dependencies
run: npm install
- name: Run unit tests
run: npm test
Automatización del despliegue
¿Qué es el despliegue continuo?
Despliegue continuo (CD) significa que el código que pasa todos los tests puede desplegarse automáticamente en producción, sin intervención manual. Se diferencia de la entrega continua en que esta última requiere aprobación humana antes del paso final.
Tipos de entornos de despliegue
- Staging / preproducción Para pruebas internas, QA y validación de negocio.
- Producción Público general. Despliegue automatizado posible si existe alta confianza.
Herramientas comunes
- Docker + Kubernetes Para contenerizar y orquestar aplicaciones.
- Terraform / Ansible Infraestructura como código (IaC).
- CI/CD pipelines Integrados en plataformas como GitHub, GitLab, Bitbucket o Jenkins.
Ejemplo básico de despliegue con GitLab CI
deploy_staging:
stage: deploy
script:
- echo "Deploying to staging"
- ./scripts/deploy_staging.sh
only:
- main
Prácticas recomendadas
- Tests rápidos y confiables
- Evita falsos positivos/negativos.
- Divide tests lentos y rápidos.
- Despliegues idempotentes
- Pueden repetirse sin cambiar el estado final del sistema.
- Rollback automatizado
- Si el despliegue falla, revertir al estado anterior automáticamente.
- Monitorización y alertas
- Detecta errores post-deploy (por ejemplo, con Prometheus, Grafana, Datadog).
- Despliegue progresivo
- Usa técnicas como:
- Canary releases
- Blue/green deployments
- Feature toggles
- Usa técnicas como:
Ventajas de una automatización bien diseñada
| Beneficio | Resultado |
|---|---|
| Menor riesgo de errores humanos | Más fiabilidad en producción |
| Integración y despliegue más rápidos | Mayor velocidad de entrega |
| Reducción de tareas repetitivas | Aumento de la productividad |
| Feedback inmediato | Mejora en la calidad del software |
| Confianza en el pipeline | Despliegues más frecuentes y seguros |
Desafíos y cómo superarlos
| Desafío | Solución |
|---|---|
| Pruebas lentas o inestables | Paralelización, refactor, mocks |
| Infraestructura compleja | Contenerización (Docker), Terraform |
| Miedo a romper producción | Feature flags, staging, pruebas exhaustivas |
| Falta de cultura DevOps | Formación, documentación, mentoría |
Cultura de equipo y automatización
Automatizar no es solo un tema de scripts y herramientas. Requiere compromiso cultural:
- Confianza en el proceso y en el equipo.
- Responsabilidad compartida por el código y su estabilidad.
- Mentalidad de mejora continua.
Un equipo bien entrenado confía en que cualquier commit en main pasará por una cadena de pruebas y despliegue sin fricción.
Paso 4: Utilizar Feature Flags
Introducción
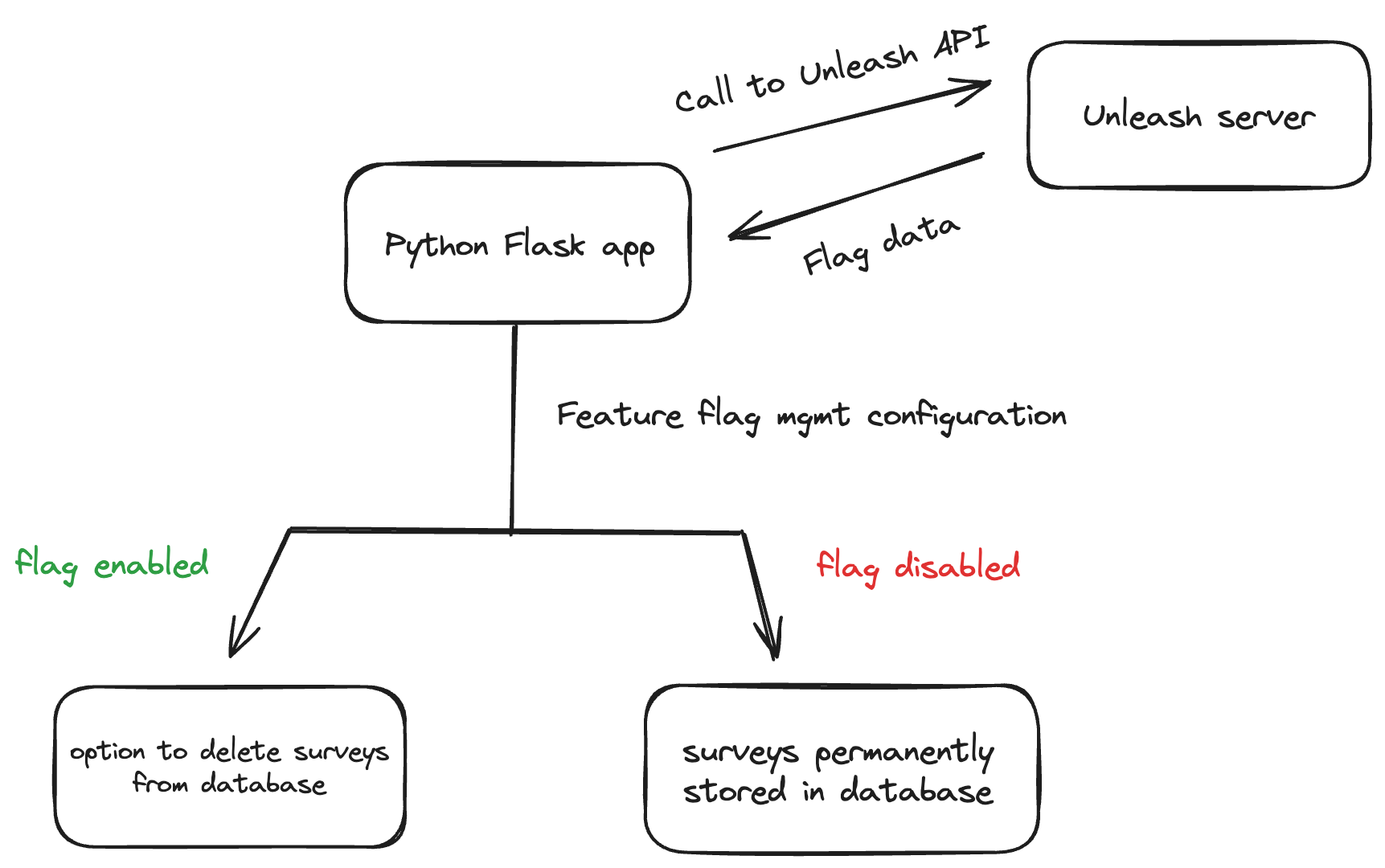
En el modelo de Trunk-Based Development (TBD), los desarrolladores integran cambios frecuentemente al trunk (rama principal), incluso si una funcionalidad aún no está terminada. Para evitar que código incompleto o inestable afecte a los usuarios, se utiliza una técnica clave: las Feature Flags, también conocidas como toggles o switches.
Una feature flag es un mecanismo que habilita o deshabilita una funcionalidad en tiempo de ejecución, sin necesidad de desplegar nuevo código. Esto permite liberar código sin activar inmediatamente la funcionalidad, y gestionar su exposición de forma segura, controlada y flexible.
¿Qué es una Feature Flag?
Una feature flag es básicamente una condición lógica en el código que evalúa si una característica debe estar activa o no. Puede estar basada en múltiples criterios: usuario, grupo, entorno, porcentaje de tráfico, tiempo, etc.
Ejemplo en pseudocódigo:
if feature_flag_is_enabled("nueva_busqueda"):
mostrar_nueva_interfaz()
else:
mostrar_interfaz_clasica()
Este enfoque permite que ambos caminos coexistan en el código sin afectar la experiencia del usuario, hasta que la nueva funcionalidad esté lista para su lanzamiento.
Tipos de Feature Flags
- Flags de desarrollo Se usan para ocultar funcionalidades en construcción. Se eliminan una vez se libera la funcionalidad.
- Flags de lanzamiento Permiten liberar una funcionalidad sin activarla para todos los usuarios. Se puede activar de forma progresiva.
- Flags experimentales (A/B) Para realizar pruebas A/B o tests multivariantes entre grupos de usuarios.
- Flags operacionales Controlan aspectos técnicos (como activar el logging extendido o modos de mantenimiento) sin redeploy.
- Flags de permisos Activan características basadas en roles de usuario o niveles de suscripción.
Ventajas del uso de Feature Flags
| Beneficio | Resultado práctico |
|---|---|
| Desacopla despliegue de activación | Puedes subir código a producción sin activarlo |
| Evita ramas largas | Todo se integra al trunk rápidamente |
| Permite releases progresivos | Activa por lotes o porcentajes |
| Facilita rollback | Desactiva la flag si algo falla |
| Mejora la experimentación | Prueba funcionalidades sin compromiso |
Cómo implementarlas correctamente
1. Estructura condicional clara
Evita la lógica compleja o anidada. Una flag debe encapsular un cambio puntual y tener un nombre descriptivo.
if (flags.nuevaBusqueda) {
mostrarNuevaBusqueda();
} else {
mostrarBusquedaAntigua();
}
2. Sistema de gestión de flags
Es común usar un archivo de configuración, una base de datos o un servicio externo. Ejemplos:
- Servicios SaaS:
- Soluciones open source/self-hosted:
- Unleash OSS
- GrowthBook
- Flipt
- Propia implementación (válida en entornos pequeños o controlados).
3. Control dinámico y seguro
La activación debe ser:
- Sin redeploys (usando paneles de control, API o dashboards).
- Auditable (con logs de cambios).
- Basada en criterios avanzados (segmentación, porcentajes, entornos).
Pruebas con Feature Flags
Las flags añaden rutas condicionales al código, lo que implica:
- Aumentar la cobertura de tests: testear ambas ramas de la condición.
- Tests específicos para usuarios con y sin la flag.
- Asegurar que los flags no rompan la compatibilidad ni la UX.
Mantenimiento y limpieza
⚠️ Un error común es olvidar limpiar flags antiguas. Esto lleva a un código complejo, lleno de condiciones innecesarias.
Buenas prácticas:
- Asocia cada flag a un ticket o historia de usuario.
- Planifica su retirada justo después de que la funcionalidad esté 100% activada.
- Usa linters o herramientas como
archaeologist(Python) para detectar flags obsoletas.
Casos de uso realistas
✔️ Despliegue progresivo
Activar una nueva funcionalidad solo para el 10% de los usuarios:
if (user.id % 10 === 0) {
mostrarNuevaFuncionalidad();
}
✔️ Activación por entorno
if ENV == "production" and feature_flag("nueva_ui"):
render_nueva_ui()
else:
render_ui_actual()
✔️ Rollback instantáneo
Si un cambio en producción rompe algo, se desactiva la flag desde el dashboard, sin hacer rollback de código.
Desafíos del uso de Feature Flags
| Desafío | Solución práctica |
|---|---|
| Acumulación de flags viejas | Auditorías periódicas y limpieza automatizada |
| Complejidad condicional | Nombres claros y cobertura de tests |
| Malas prácticas (flag driven dev) | Usarlas solo para control de comportamiento |
| Pérdida de visibilidad | Dashboards centralizados y métricas |
Cultura del equipo y Feature Flags
El uso efectivo de feature flags requiere una cultura orientada a:
- Integración continua real.
- Releases frecuentes sin miedo.
- Confianza mutua en los cambios.
- Observabilidad post-release.
Las flags se convierten en herramientas de colaboración, no solo líneas de código.
Paso 5: Capacitar al equipo
Introducción
Adoptar Trunk-Based Development (TBD) no es solo una cuestión de cambiar el flujo de trabajo con Git. Requiere un cambio profundo en la mentalidad del equipo de desarrollo. Significa comprometerse con prácticas como la integración continua, la automatización, las pruebas rigurosas, el uso de feature flags y, sobre todo, una colaboración fluida y constante.
Ninguna herramienta, configuración o pipeline será suficiente si el equipo no entiende, cree y domina las prácticas que hacen sostenible el Trunk-Based Development. Por eso, la capacitación del equipo es una inversión estratégica ineludible.
¿Por qué capacitar?
- Para evitar la resistencia al cambio.
- Para asegurar que todos los miembros dominan las prácticas y herramientas de TBD.
- Para fomentar una cultura de mejora continua, comunicación y responsabilidad compartida.
- Para lograr una adopción orgánica, efectiva y duradera del nuevo modelo de trabajo.
Principios de una buena capacitación
- Formación técnica y cultural
- No basta con enseñar a usar
git pulloCI/CD. - Hay que explicar el “por qué” de cada práctica.
- Las sesiones deben combinar teoría, casos reales y práctica.
- No basta con enseñar a usar
- Aprendizaje progresivo y constante
- No se trata de una única charla inicial.
- TBD se aprende por fases, con refuerzo continuo y adaptado a cada rol.
- Capacitación transversal
- No solo los desarrolladores deben estar formados.
- También QA, DevOps, product managers y líderes deben entender cómo encajan en el nuevo modelo.
Contenidos clave a capacitar
🧠 Filosofía y fundamentos de TBD
- Qué es TBD y por qué se adopta.
- Comparación con Git Flow y otras estrategias.
- Ciclo de vida de una funcionalidad desde idea hasta producción.
⚙️ Prácticas técnicas concretas
- Integración continua real (commits frecuentes a
main). - Automatización de pruebas y despliegues.
- Feature flags y ramas de corta duración.
- Pull requests pequeñas, rápidas y eficientes.
🛠️ Herramientas del ecosistema
- Sistemas de CI/CD (GitHub Actions, GitLab CI, Jenkins…).
- Sistemas de gestión de flags (LaunchDarkly, Unleash, Flagsmith…).
- Linters, formateadores automáticos, test runners.
- Observabilidad y rollback.
🧪 Testing eficaz
- Qué tipos de tests aplicar (unitarios, integración, E2E).
- Cómo estructurar el código para testabilidad.
- Cómo detectar errores antes de llegar al trunk.
🗣️ Comunicación y colaboración
- Cultura de revisión constante y constructiva.
- Resolución rápida de conflictos.
- Visibilidad compartida del trabajo en curso.
- Refuerzo del feedback continuo.
Métodos de capacitación
✅ Talleres prácticos
- Simular ciclos de desarrollo con ramas cortas y PRs rápidos.
- Romper y reparar pipelines.
- Crear y eliminar feature flags en ejercicios reales.
✅ Katas y ejercicios guiados
- Ejercicios de TDD que incluyen integración continua.
- Flujos de trabajo con conflictos controlados.
✅ Pair programming y mob programming
- Desarrollar juntos permite transmitir buenas prácticas en tiempo real.
- Ayuda a igualar el conocimiento entre perfiles senior y junior.
✅ Documentación interna actualizada
- Guías paso a paso para usar el flujo de trabajo TBD.
- Checklists de buenas prácticas.
- Casos de éxito del propio equipo.
✅ Mentores internos
- Asignar “champions” del cambio: desarrolladores experimentados que acompañen a sus compañeros.
- Resolución rápida de dudas, code reviews ejemplares, refuerzos positivos.
Acompañar el cambio cultural
Capacitar también implica romper viejos hábitos. Por ejemplo:
| Mal hábito | Nueva práctica con TBD |
|---|---|
| Ramas largas de semanas | Ramas pequeñas, de horas o 1-2 días |
| “Merge cuando todo esté terminado” | “Merge temprano, con feature flags” |
| Revisiones lentas y extensas | Revisiones ligeras y continuas |
| Depender del QA al final | Automatizar tests desde el principio |
| Culpa individual por errores | Responsabilidad colectiva del trunk |
El liderazgo técnico debe reforzar con el ejemplo: usar el trunk correctamente, hacer revisiones frecuentes, aplicar tests y no romper la build. Nada enseña más que la coherencia entre el discurso y la práctica.
Métricas para evaluar la capacitación
| Indicador | Cómo medirlo |
|---|---|
| Tiempo medio entre merges | Más bajo = mayor frecuencia de integración |
| Tamaño medio de PRs | Más pequeño = cambios más manejables |
| Porcentaje de cobertura de tests | Más alto = más confianza en integraciones |
| Tiempo de revisión de PRs | Más corto = mayor fluidez de colaboración |
| Incidencias tras despliegues | Menor número = mejor calidad |
Estos indicadores pueden servir para reforzar aprendizajes y mostrar avances concretos.